
Why the World's Oldest Mathematics Could Transform AI
India just committed $200 billion to AI. Sam Altman, Sundar Pichai, and Dario Amodei flew to New Delhi. Sovereign language models are scaling across 22 Indian languages. But every model runs on imported architecture, the same transformers, and mathematics running everywhere else.

- Author: Nicole Flynn
- Date: March 2026
- Dependencies: None
- Published: March 2026
- Copyright: 2026 Symfield PBC. CC-BY-NC-ND 4.0.
Publication Record: This document has been cryptographically timestamped and recorded on blockchain to establish immutable proof of authorship and publication date.
When Silicon Valley Comes Bearing Gifts
In February 2026, Sam Altman, Sundar Pichai, and Dario Amodei arrived in New Delhi. More than $200 billion in investment commitments soon followed. India was officially welcomed into the global AI race, on terms written in San Francisco.
The IndiaAI Mission launched sovereign language models. Sarvam AI began scaling across 22 Indian languages. Krutrim, BharatGen, Gnani.ai, and a dozen others followed. Each announcement was hailed as proof that India had “arrived.”
Arrived where? At the same transformer architecture, the same attention mechanisms, the same gradient descent, and the same collapse-based mathematics are already running everywhere else. The GPUs are NVIDIA. The chip architecture is American. The CUDA software stack is proprietary. The transformer frameworks are built on PyTorch (Meta) and TensorFlow (Google). The training methodologies come from papers published by OpenAI, Google, and Anthropic. The benchmark standards that determine what counts as "good AI" are set in San Francisco.
India is building power plants to run someone else's machines executing someone else's math optimized to someone else's benchmarks. That's not sovereignty. That's infrastructure for dependency.
And it lines up with a recent structural analysis of twelve leading US and Chinese models that found 88.1% average isomorphism across key dimensions including architecture type, training paradigm, optimization method, scaling approach, and mathematical foundation, same paradigm, different flags (Flynn, 2026). India is now wiring itself onto that same grid, with Western capital, Western code, and Western assumptions about what mathematics is for. This should give pause to anyone who understands what India actually brings to the table.
Culture is not a commodity; it is a compass. India possesses the world’s oldest living mathematical tradition that treats structures as things to be perceived rather than constructed. It discovered zero as a mathematical object, formalized multiple orders of infinity centuries before Cantor, and produced one of the most remarkable mathematical minds in history. That tradition is not a historical footnote. It is a living orientation toward mathematics that the West does not possess and cannot replicate. It is the one asset the $200 billion cannot buy, because India already owns it, and the one asset currently being left out of the conversation.
This article asks one question, What if India also built AI from its own mathematical heritage, in addition to the tools that already work? Not as a rejection of Western engineering, which is delivering real value today. But as recognition that the most ancient non-collapse tradition on Earth may have something essential to offer the most important technology in human history, before the window closes under the weight of 38,000+ GPUs and ₹10,372 crore already committed to more of the same.
India’s Mathematical Heritage
I write as an outsider, an American researcher focused on perceptual non-collapse mathematics who immediately recognizes the Indian tradition when observed. I do not speak for Indian mathematical heritage or to prescribe what India should do. Indian mathematicians, scholars, and technologists are natively positioned to judge whether the connections made here are substantive. This piece is an observation and an invitation, not a prescription.
Indian mathematicians, Ramanujan, Brahmagupta, Aryabhata, worked as if mathematical truth already existed and the task was to perceive it directly. The Western tradition, from Greece onward, builds mathematics through axioms, deductions, and theorems. Knowledge is constructed step by step; math is something humans make.
India approached mathematics differently. The foundational assumption was that structures exist independently and perception is the method. Not construct. Not prove. Perceive. The shapes simply are; the mathematics follows the shapes.
This was not naive or pre-scientific. It was philosophically rigorous. The Nyaya school of Indian philosophy, dating to at least the 2nd century BCE, formally established pratyaksha, direct perception, as a pramana, a valid and independent means of acquiring knowledge. This wasn't a poetic metaphor. It was a systematically debated epistemological framework that defined the conditions under which direct perception produces reliable knowledge, when it fails, and how it relates to other means of knowing such as inference (anumana) and testimony (shabda). Indian philosophers spent centuries refining these distinctions with a precision that rivals anything in Western analytic philosophy.
Western epistemology has no equivalent category. It recognizes empirical observation, logical deduction, and inductive inference. It does not formally recognize direct apprehension of abstract structure as a valid way of knowing. When it happens, and it demonstrably does, the Western framework has nowhere to put it. It becomes "intuition" (vague), "unconscious processing" (reductive), or "anomaly" (dismissive).
India gave the world zero not merely as a placeholder but as the presence of absence, a mathematical object representing what is not there, which turns out to be as structurally important as what is. India gave the world infinity not as a vague concept of bigness but as a formal mathematical object. Jain mathematicians classified different orders of infinity, enumerable, innumerable, and infinite, with further subdivisions within each, centuries before Georg Cantor's work on transfinite numbers in the 1870s shocked Western mathematics.
The tradition was computational rather than axiomatic. It produced results, patterns, series, and relationships. Brahmagupta in the 7th century established rules for arithmetic with zero and negative numbers. Aryabhata in the 5th century calculated pi to four decimal places and described the Earth's rotation. Madhava of Sangamagrama, in the 14th century, developed infinite series expansions for trigonometric functions, what the West calls Taylor series, roughly 300 years before Brook Taylor. These were not tentative guesses. They were precise, functional, verified results. Proof of logical necessity, in the Western sense, was secondary to the fact that the mathematics worked and could be perceived to be true.
Indian mathematicians such as Ramanujan, Brahmagupta, and Aryabhata worked as if mathematical truth already existed in the universe and their task was to perceive it directly rather than construct it through axioms and proofs. To the Western mind, trained in step-by-step deduction, this can seem almost mystical. Yet within India's tradition, accessing mathematical structures through direct perception rather than formal construction was not mystical at all. It was epistemologically grounded, philosophically defended, and practically validated across more than two millennia of results.
The West has a word for knowledge it cannot explain through its own framework, mysticism. India had a word for the same phenomenon, knowledge.
G.H. Hardy, Ramanujan's collaborator at Cambridge, later described what he found in the notebooks:
"The limitations of his knowledge were as startling as its profundity. Here was a man who could work out modular equations and theorems... to orders unheard of, whose mastery of continued fractions was... beyond that of any mathematician in the world, who had found for himself the functional equation of the Zeta function and the dominant terms of many of the most famous problems in the analytic theory of numbers; and yet he had never heard of a doubly periodic function or of Cauchy's theorem, and had indeed but the vaguest idea of what a function of a complex variable was..." - G.H. Hardy
Western AI comment on Pratyabhijñā
In preparing this article, three independent AI systems, Claude (Anthropic), Grok (xAI), and GPT (OpenAI), were asked to identify and describe this mode of cognition. All three converged on the same conclusion: it is real, documented in fragments across multiple Western disciplines, and no unified framework for it exists. All three independently identified India's epistemological tradition as the closest formal account. None could say what it actually is, only that it produces verifiable results.
Three AI systems built on collapse-based mathematics, trained predominantly on Western knowledge, each independently arrived at the same gap in their own foundations, and each pointed to the same tradition to fill it. They could describe the correlates, name the brain regions, cite the research fragments, and confirm the outputs are valid. They could not explain the process, because the epistemological framework required to explain it was not included in the paradigm they were built on.
This is not an anecdote. It is a reproducible demonstration of the blind spot this article is about.
Pratyabhijñā (प्रत्यभिज्ञा)
Etymologically: prati ("re-" or "again") + abhi ("closely" or "in truth") + jñā ("to know"). Literally: "to know again closely", re-cognition.
The term is usually translated as "recognition." The word has been explained as knowledge of an object to which one turns back and which then faces the knower. Wikipedia
Pratyabhijñā is not remembrance. It does not result from memory. It results from a synthetic activity of the mind that destroys the misconceptions veiling the real nature of what is being perceived.
This distinction is critical. Pratyabhijñā is not learning something new. It is not constructing knowledge through steps. It is not recalling something forgotten. It is the direct perception of what was always present but obscured, a recognition so immediate that it carries its own validity.
The broader epistemological framework that houses this concept is equally rigorous. Indian philosophy formally classifies pramāṇas, valid means of acquiring knowledge. While the number varies by school, most recognize at least three: pratyakṣa (direct perception), anumāna (inference), and śabda (reliable testimony). Some schools recognize six. All major schools of Indian philosophy accept pratyakṣa, direct perception, as independently valid. It is not derived from inference. It does not require logical proof to be considered knowledge. It stands on its own.
Moreover, Indian philosophers did not treat direct perception as a vague capacity. They debated its conditions rigorously across centuries, defining when it produces valid knowledge, identifying its failure modes, distinguishing determinate from indeterminate perception, and classifying unusual forms of perception including pratibhā (intuition), induction from specifics to universals, and the perception of prior states by observing present conditions. These are not folk categories. They are formal epistemological distinctions refined through sustained philosophical argument across multiple competing schools over more than two millennia.
Western epistemology has inference, empirical observation, and logical proof. It does not have a formal category for "I perceived this structure directly and it turned out to be correct." When Ramanujan reported seeing mathematics delivered to him complete in dreams, the Western framework had nowhere to put this except "genius" or "anomaly" or "intuition", words that describe nothing and explain less. India had pratyabhijñā: a rigorous concept, embedded in a formal epistemological system, that describes exactly what Ramanujan reported, and what any practitioner of this cognition experiences.
The West has a word for knowledge it cannot explain through its own framework, mysticism. India had a word for the same phenomenon, knowledge.
And this begs the question, if western education allowed non-linear reasoning, if validation didn't require stepwise proof first, if translation tools improved, primary users would go from estimates of 1-5% of the population accessing non-linear reasoning to much higher.
India's pratyakṣa tradition didn't just recognize this mode. It created the conditions for it to develop, contemplative practices, mathematical cultures that valued results over proof chains, philosophical frameworks that treated direct perception as formally valid knowledge. The tradition didn't produce Ramanujan by accident. It produced an environment where someone like Ramanujan could develop instead of being suppressed. That's what's at stake. Not just AI architecture. Not just mathematical heritage.
Ramanujan and the Art of Direct Perception
No figure better embodies this perceptual tradition than Srinivasa Ramanujan (1887–1920). Born in humble circumstances in Erode and largely self-taught, Ramanujan produced thousands of theorems, identities, and formulas, many in number theory, infinite series, partitions, modular forms, and mock theta functions, that still astonish mathematicians today.
What made his process remarkable was not just the depth of his results, but how he arrived at them. Ramanujan frequently could not supply the formal Western-style proofs that his Cambridge contemporaries demanded. Yet time after time, his formulas proved correct, often decades or even a century later, when others finally developed the tools to verify them.
Ramanujan himself was open about the source of his insights. He credited his family deity, the Goddess Namagiri Thayar of the Namakkal temple, with revealing the mathematics to him. He described how, in dreams, the goddess would appear and present entire formulas. He spoke of seeing scrolls of complex mathematical content unfold before his eyes or equations written on a red screen, or even “on his tongue.” He would wake and transcribe what he had seen. He famously said, “An equation for me has no meaning unless it expresses a thought of God.”
To Ramanujan, mathematics was not an invention of the human mind through step-by-step logic, but a revelation of pre-existing truth. The structures were already there; his role was to perceive and record them faithfully.
Western mathematicians like G.H. Hardy were initially baffled. How could someone produce such precise, profound results without rigorous deduction? Hardy later acknowledged the extraordinary power of Ramanujan’s intuition. Yet within the Indian tradition, this was not mysterious, it was consistent with a long lineage that valued direct perception over constructed proof.
Ramanujan’s mathematical insights were concrete, original, and often far ahead of their time, delivered as complete structures rather than pieced together through incremental proof. One famous example occurred during a hospital visit from Hardy. Mentioning the taxi number 1729 as “rather dull,” Ramanujan instantly replied that it was actually very interesting, the smallest positive integer expressible as the sum of two positive cubes in two different ways (13+123=93+103=1729) He had perceived the property at a glance.
His work on infinite series included rapidly converging formulas for 1/π, such as
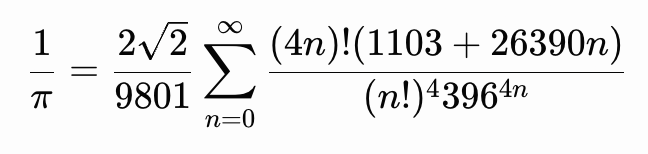
and similar identities. These were so efficient that they were later used to compute billions of digits of π with extraordinary speed, decades before modern computers could match the precision his intuition had unlocked.
In partition theory, Ramanujan (collaborating with Hardy) derived the asymptotic formula for the partition function p(n), the number of ways to write n n n as a sum of positive integers. He also discovered striking modular congruences such as, p(5n+4)≡0(mod 5), p(7n+5)≡0, and p(11n+6)≡0(mod11). These patterns emerged intuitively; the deep proofs came later.
Perhaps most visionary were the mock theta functions he introduced in his final letter to Hardy in 1920, just months before his death at age 32. Ramanujan described a new class of functions that behaved like theta functions near the unit circle but were not quite the same, without providing a formal definition or complete theory. For decades they remained mysterious. Only in the 21st century did mathematicians (notably Sander Zwegers) complete the framework, revealing profound connections to quantum modular forms, black-hole entropy in string theory, and quantum gravity. What Ramanujan had perceived as isolated “beautiful” functions turned out to be gateways to entire new branches of mathematics and physics.
Ramanujan’s notebooks, filled with thousands of entries often lacking proofs, continue to yield new discoveries. This is the living heart of India’s non-collapse mathematical orientation, trust in the existence of the structure, and confidence that sincere perception can access it without forcing it into a linear chain of collapsed logical steps.
This is not romantic folklore. It is a documented mode of mathematical cognition that produced results the axiomatic tradition later struggled to catch up to. It shows what becomes possible when mathematics is treated as recognition rather than fabrication.
What Perceptual Mathematics Actually Means
Western mathematics rests on a single foundational move, collapse. You take something that exists in relationship, in superposition, in ongoing structure, and you force it into a definite value. Recent work on perception-as-recursion shows that coherence is maintained through structured opposition, not resolution. Systems that force alignment lose information and collapse into redundancy; architectures that hold productive tension open new pathways for adaptation.
Squaring (a2) is the purest example, a thing multiplied by itself with no productive opposition, no new information, only self-amplification. The Pythagorean theorem (a2+b2=c2) works only after lengths have already been collapsed into scalars.
Every core operation in modern AI follows the same logic:
- Measurement → definite value
- Optimization → convergence
- Computation → termination
Gradient descent, backpropagation, loss functions, attention-weighted sums, all reduce relational structure into fixed outputs. The system terminates. The door closes.
The architecture is extraordinarily effective for many tasks. But it carries a built-in ceiling, it cannot preserve the relational structure that constitutes much of biological and cognitive intelligence. It can approximate. It cannot fully maintain. This direction aligns with the question already being explored, ‘How do we build AI architectures that naturally maintain coherence through opposition, making forced alignment unnecessary?’ It treats current models not as a ceiling, but as one cross-section of a larger, already-complete relational substrate.
India’s $200 Billion Bet
India is executing brilliantly within the existing paradigm. The IndiaAI Mission has deployed 38,000+ GPUs. Sarvam’s mixture-of-experts model activates roughly 1 billion of 30 billion parameters per token, impressive engineering. BharatGen, Krutrim, Gnani.ai, and the twelve shortlisted organizations are delivering multilingual, voice-first, sovereign models at population scale. India now ranks third globally in AI competitiveness.
Yet every one of these models rests on imported foundations, transformers, attention, backpropagation, gradient descent. The same structural analysis (Flynn, 2026) would score Indian models comparably to US and Chinese systems on architecture, training paradigm, optimization, scaling, and mathematical substrate. Sovereignty lives at the interface layer (language, data, governance). The mathematics underneath remains identical.
This is not a criticism of the engineers solving immediate problems with the best available tools. It is a question of whether this should be the only thing India builds, and whether the gravitational pull of $200 billion will crowd out the possibility of also building something else.
What Current AI Cannot Preserve
Today’s systems:
- Approximate relationships but do not maintain them
- Terminate processes into discrete outputs
- Lack persistent relational coherence
They approximate relational structure. They do not maintain it.
Biology offers a contrasting picture. The MICrONS project (Machine Intelligence from Cortical Networks) produced one of the most detailed wiring diagrams of mammalian cortex to date, a cubic millimeter of mouse visual cortex with structural mapping of over 200,000 neurons and hundreds of millions of synapses, co-registered with functional activity data. Analysis of this connectome shows that the most highly connected neurons tend to maintain geometric opposition or complementary differences with their neighbors, rather than converging toward forced similarity or alignment. One reported correlation in relevant relational metrics reached ρ = +0.63 (with high statistical significance), suggesting that biological intelligence sustains productive tension and ongoing relational structure instead of collapsing everything into uniform or terminal outputs. Symfield analysis of the same MICrONS dataset frames this pattern as coherence maintained through geometric opposition: highly connected hub neurons preferentially link to those with complementary response properties and temporal dynamics, producing strong positive correlations (ρ ≈ +0.63 for hubs, p < 10⁻¹⁰) that invert expectations of similarity-based wiring. This opposition enables integration and computation rather than redundancy. In this view, biological intelligence preserves ongoing relational structure by holding productive tension open, rather than resolving it into uniform alignment.
What Perceptual AI Would Look Like
While the concept of perceptual or opposition-preserving mathematics may not immediately appeal to engineers focused on delivering fast, measurable results with today’s proven tools, it represents a deeper architectural possibility worth exploring alongside existing approaches.
This article is not suggesting India copy anyone else’s mathematics. It has its own, ancient and profound. What an AI built on Indian perceptual principles, perception over construction, maintained relationships over forced collapse, would actually look like, no one knows. Nobody has tried at scale. That is both the loss and the extraordinary opportunity.
We can glimpse hints in nature and in Ramanujan’s own process. The brain does not output terminal answers, it sustains living webs of relationships. Ramanujan did not “build” his formulas through deduction, he recognized what was already there, often delivered complete in moments of inspired perception, as with the 1729 taxicab number, his rapidly converging series for π, and the visionary mock theta functions.
A computational architecture rooted in the same orientation might prioritize ongoing coherence, shape-preserving operations, and non-terminal processes that allow structure to unfold rather than converge to a single fixed point. This direction echoes observations from biology: systems that route around constraints through geometric reconfiguration, whether slime mold solving mazes via dynamic protoplasmic tubes or neural hubs sustaining recursion through complementary pairing. Such architectures would treat maintained difference and productive tension as generative signal, not noise to be collapsed.
Consider a simple contrast. When a current transformer-based system processes a sentence, it ultimately selects one next token, discarding all other possibilities. The rich relational field, the tensions, oppositions, and contextual ambiguities from which that token emerged, collapses and is lost. The system cannot return to what it discarded. A perceptual architecture would not discard that field. It would hold the relational structure, the productive tensions between possible meanings, the unresolved ambiguities, the complementary oppositions, as living, available information. The “answer” would not be a single point but a sustained configuration, more like a musician holding a resonant chord than striking a single note.
What this means practically, for latency, compute cost, user interaction, or real-world performance, remains an open engineering question. These can only be answered by building it. The deeper point is that the mathematical foundation for such an architecture already exists in principle, and the tradition best equipped to develop it has been practicing mathematics this way for over two thousand years.
The Civilizational Loss, and the Opportunity
India already possesses the conceptual foundations for a different architecture, shape-preserving operations, non-terminal computation, mathematics that perceives rather than constructs, relationships that are maintained rather than measured into submission.
The scholars best positioned to understand these principles may not be at MIT or Oxford. They may be at IIT, ISI Kolkata, or the Chennai Mathematical Institute. Not because of geography, but because their inherited tradition already treats mathematics this way, as Ramanujan lived it.
Why It Hasn’t Happened Yet
The answer is largely institutional, not intellectual. Global academia and funding ecosystems reward publication in Western journals using Western frameworks. Resources flow toward proven architectures with clear, measurable benchmarks on established tasks. Careers advance through incremental progress inside the dominant paradigm. Ramanujan once had to mail his notebooks to Cambridge to be taken seriously. A century later, the incentive structure has not fundamentally changed.
At the same time, it is fair to ask whether the Western collapse-based framework is already sufficient for what most AI applications need today. Transformers and gradient descent demonstrably work for language modeling, pattern recognition, and many practical services. They deliver results at scale and create real economic value. The burden of proof rightly falls on anyone proposing an alternative foundation, they must show not only that it is conceptually coherent, but that it can deliver comparable or superior performance on meaningful benchmarks, or unlock capabilities the current paradigm fundamentally cannot reach. This article does not claim to have settled that question. It simply argues that the question is worth asking, especially by the culture whose own mathematical heritage already points in a different direction.
A Note on Boundaries
Perceptual mathematics as collapse-based mathematics excels when definite values and termination are required, building a house, running an engineering calculation, or executing a logistics schedule. It works and should continue to be used where appropriate.
However, living systems operate differently. A biological organism does not "terminate" at every moment of computation; it maintains ongoing relational coherence across time, even as individual cells die and are replaced. Cognition does not produce final, static answers, it sustains evolving webs of perception, memory, and adaptation.. When we apply collapse mathematics to fundamentally relational domains, we gain powerful functional approximations, yet we still miss the persistent structure that actually constitutes living intelligence.
The Path Forward
India does not need to compete with OpenAI at building ever-larger transformers. It is uniquely positioned to build what transformers fundamentally cannot be, AI that maintains relational coherence, that does not force collapse, that operates the way India’s own mathematical tradition, exemplified so powerfully in Ramanujan, has always understood reality to work.
The mathematics India already knows is the mathematics AI does not yet have.
The question is no longer whether the Western toolkit is valuable. It is whether India will also choose to build from its own heritage, creating something only that tradition can produce. The world needs more than one mathematical paradigm for intelligence. India is the culture best placed to supply it. Not instead of what is already working. In addition to it. That is the opportunity. And the window is still open.
Most imperative to consider, this is about whether an entire mode of human cognition gets developed or buried. India, you decide.
Nicole Flynn is the Founder and CEO of Symfield, research focused on non-collapse relational mathematics, field-coherent computation, and cross-domain intelligence frameworks.
Key Sources and Context Referenced
Flynn, N. (2026). The Mirror Grid: Structural Monoculture in Global AI Development. OSF Preprint. https://doi.org/10.17605/OSF.IO/YTQS8
- Indian mathematical heritage and Ramanujan: Accounts of visions from Goddess Namagiri, the quote “An equation for me has no meaning unless it expresses a thought of God,” the 1729 taxicab anecdote, rapidly converging π series, partition congruences and asymptotic formula, mock theta functions (and their later connections to quantum physics and string theory).
- IndiaAI ecosystem (2025–2026): ₹10,372 crore outlay, 38,000+ GPUs, India AI Impact Summit pledges, Sarvam, Krutrim, BharatGen, Gnani.ai, Stanford Global AI Vibrancy rankings.
- Non-collapse mathematics and MICrONS: Symfield work on the Geometric Opposition Operator; MICrONS connectome dataset (mouse visual cortex structural + functional mapping).
Indian Mathematical Heritage:
- Ramanujan's direct perception of mathematical formulas without formal proof
- Brahmagupta and Aryabhata's computational (vs. axiomatic) tradition
- Jain mathematicians' work on orders of infinity predating Cantor
- India's invention of zero as mathematical object (presence of absence)
India AI Ecosystem (2025-2026):
- IndiaAI Mission: ₹10,372 crore outlay, 38,000+ GPUs deployed
- India AI Impact Summit 2026: $200B+ investment commitments, 88 countries endorsed New Delhi Declaration
- Sarvam AI: India's first sovereign LLM, 22 Indian languages, selected under IndiaAI Mission
- Krutrim AI (Bhavish Aggarwal/Ola): Krutrim-2 12B-parameter multilingual model
- BharatGen: National mission, IIT Bombay consortium, government-backed
- Gnani.ai: 14B voice-first model for Indian languages
- 12 organizations shortlisted for indigenous foundational model development
- India ranked 3rd globally in AI competitiveness (Stanford 2025 Global AI Vibrancy Tool)
Structural Monoculture:
- Symfield Mirror Grid analysis: 88.1% structural isomorphism across US and Chinese AI
- Western architectural foundations (transformers, attention, backpropagation) adopted globally
- Sovereign AI initiatives building on imported mathematical paradigms
Non-Collapse Mathematics:
- Symfield PBC: Patent applications filed for non-collapse AI architectures
- Geometric Opposition Operator (⊗): Validated on MICrONS neural connectome data
- Biological neural systems organize through complementary opposition (ρ = +0.63, p < 10⁻¹⁰)
- Brain maintains relationships rather than computing terminal outputs